Publicado nos Anais do INFOIMAGEM 2001, Cenadem Outubro/2001. Para imprimir este paper com melhor qualidade (principalmente nos gráficos), recomendo fazer o download da versão em postscript.
Inteligência Artificial: Presente, Passado e Futuro
Sergio C. Navega
snavega@attglobal.net
Intelliwise Research and Training
http://www.intelliwise.com/snavega
Setembro de 2001
Resumo
Estamos em pleno verão de 1956. No Dartmouth College, Estados Unidos, o Summer Workshop acaba de se iniciar. Um grupo de criativos e jovens cientistas estão reunidos para discutir uma nova e revolucionária idéia: como construir máquinas inteligentes. O grupo era composto por Marvin Minsky, Herbert Simon, Allen Newell e John McCarthy, entre outros. Mal sabiam eles que esse encontro estaria iniciando uma saga que por décadas perseguiria o difícil objetivo de obter máquinas inteligentes. Mal sabiam eles que o problema sobre o qual estavam discutindo era muito mais complexo do que imaginavam.
O próprio conceito de inteligência é algo bastante difícil de se definir. Por essa razão, Inteligência Artificial foi (e continua sendo) uma noção que dispõe de múltiplas interpretações, não raro conflitantes ou circulares. Neste artigo vamos observar algumas das técnicas desenvolvidas nesses quase cinquenta anos de pesquisas. Veremos que várias dessas técnicas fazem sentido em certas formas de se definir inteligência. Contudo, cada uma delas parece deixar de fazer sentido se nossa interpretação é ligeiramente diferente.
As Primeiras Esperanças
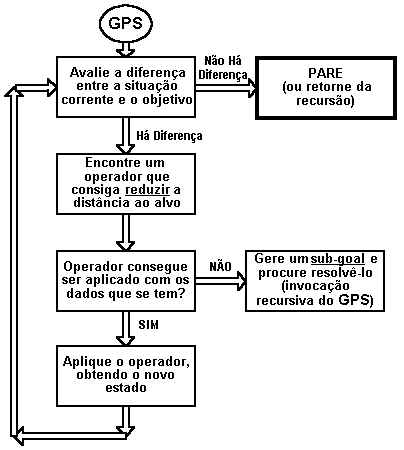
Newell e Simon apresentaram no encontro de 1956 um programa chamado LT, o Logic Theorist. O programa era revolucionário para a época, pois conseguia provar certos teoremas da aritmética. O LT foi um dos primeiros programas que foram empregados na manipulação de informação não numérica. O sucesso do LT foi seguido pelo GPS (General Problem Solver), também concebido pelos dois cientistas. O GPS opera através de uma técnica que faz muito sentido: o chamado Means-Ends Analysis. Se queremos alcançar um objetivo em particular, nossa preocupação deve ser escolher (dentre várias) uma atitude que nos aproxime desse objetivo, ou seja, que reduza a distância entre o estado atual e o estado final desejado. Suponha que meu objetivo é ir ao trabalho de manhã, a partir de minha residência. O que me separa de alcançar este objetivo? Ora, uma questão de distância. Como fazer para reduzir distâncias? Andando, correndo ou usando um automóvel. Seleciono a opção de ir de automóvel, já que a distância é grande (ou seja, a atitude "usar um automóvel" é a mais adequada ao meu objetivo de reduzir grandes distâncias). Mas verifico que meu carro não dá a partida, está com a bateria descarregada. Tenho agora um novo objetivo, o de consertar este problema. Como obter uma bateria carregada? Chamando um auto-elétrico. O que preciso para contatá-lo? Certamente alguma forma de comunicação. Posso gritar, ou telefonar. A opção mais adequada, novamente dada a distância, é usar um telefone.
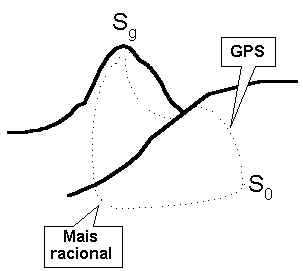
Boa parte dessas perguntas eram resolvidas pelos seres humanos que operavam o GPS, e não pelo próprio programa. A inteligência, portanto, não parecia estar totalmente contida no programa, mas dependia muito do uso por alguém que soubesse especificar inteligentemente os objetivos e as ações possíveis para resolvê-lo.
Símbolos e Inteligência
O GPS é legítimo representante de uma linha de sistemas que tem nos símbolos o principal conceito básico. A chamada visão "simbolicista" da inteligência parte de um princípio geral que foi proposto de forma explícita pela primeira vez em 1976, também por Newell e Simon. O princípio é conhecido pela sigla PSSH (Physical Symbol System Hypothesis), a hipótese do sistema físico simbólico:
"Um sistema simbólico físico tem os meios necessários e
suficientes para a ação inteligente genérica"
Newell & Simon (1976)
Este princípio precisa ser entendido como uma hipótese, ou seja, algo que assumimos como sendo "verdade", mesmo sem dispormos de uma forma sólida de justificação. Sabemos que os seres humanos usam símbolos, mas seria essa habilidade responsável por tudo o que precisamos para explicar o seu comportamento inteligente? Essa hipótese carrega, na verdade, uma alegação muito forte, pois fala em meios necessários e suficientes. Tudo o que é feito na IA Simbólica requer que aceitemos esse princípio e se ele não for inteiramente correto, podemos ter alguns problemas. Diversos trabalhos posteriores a essa data criticaram a hipótese, mas por enquanto vamos observar até onde ela nos leva. Neste caso, parece ser mais interessante aprender com nossos erros do que com nossos acertos.
Representando Conhecimento Com a Lógica
Uma das formas mais comuns de se representar conhecimento em forma simbólica é através da Lógica de Primeira Ordem (FOL, First Order Logic). Usamos expressões que codificam nossas inferências genéricas sobre variáveis. Veja um exemplo:![]()
Nesta expressão estamos dizendo que para qualquer x, tal que x seja advogado, então podemos concluir que x é rico. Dessa maneira, conseguimos representar um tipo de conhecimento através de uma expressão genérica, pois x pode assumir qualquer valor. Podemos continuar com nossa representação adicionando outra expressão:
![]()
![]()

Falamos ao computador que João é um advogado. Dizemos que ele tem uma casa. Pronto, daí em diante o computador irá "raciocinar" que João gasta muito para manter sua casa, pois seguirá a cadeia de inferências genéricas que colocamos previamente. Longas cadeias de raciocínio como essas podem ser introduzidas e o efeito das inferências feitas pelo computador são simplesmente surpreendentes, principalmente para pessoas que não sabem o teor daquilo que foi colocado. Mas fica uma questão pendente: seria essa habilidade de executar sequências de inferências lógicas uma demonstração de inteligência? Não seriam essas expressões simplesmente uma forma de "congelar" a inteligência de quem colocou-as no computador?
Os Frames de Minsky
Além da vertente lógica, existem outras que procuram representar o conhecimento através de mecanismos diferentes. Um desses mecanismos são os "frames", popularizados por Marvin Minsky (1975). Nos frames, temos uma estrutura de "escaninhos" nos quais colocamos etiquetas e valores: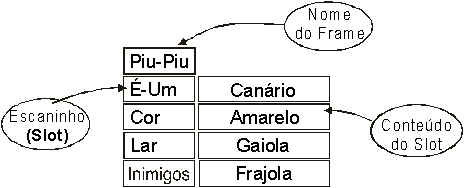
Os frames permitem a representação de relações hierárquicas entre conceitos e através dessas relações podemos inferir propriedades e responder a certas questões (na verdade, os frames podem ser convertidos para expressões em lógica de primeira ordem). Abaixo temos um exemplo de uma rede de frames interligada:
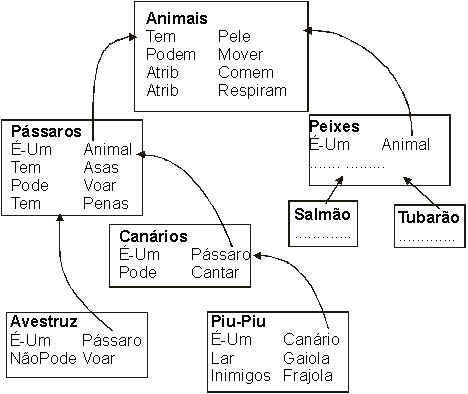
Observe o frame inferior. Será que o Piu-Piu pode voar? Se observarmos no frame correspondente ao Piu-Piu, vamos notar que nada é dito explicitamente sobre isso. No entanto, o escaninho "É-Um" nos informa que ele é uma instância de uma noção mais abrangente, a do Canário. Seguimos o apontador e vemos que ele nos leva a um frame que diz algumas coisas sobre canários, inclusive que eles são Pássaros. Novamente seguimos esse apontador e finalmente encontramos o frame "Pássaros", uma instância hierarquicamente superior onde a propriedade Voar está explicitada. Concluimos, assim, que o Piu-Piu pode voar. As idéias de herança de propriedades hierarquicamente superiores são úteis não apenas nos frames, mas também em praticamente todas as modernas linguagens de programação orientadas a objeto. Da mesma forma que com expressões lógicas, um computador manipulando frames pode executar operações de forma surpreendentes. Mas ainda assim, proponho relutar em aceitar isto como uma demonstração de inteligência.
Os Sistemas Especialistas
O auge dos sistemas simbólicos foi atingido em torno da década de 1980, com os Sistemas Especialistas, programas que dispunham de uma "Base de Conhecimentos" no qual estavam codificadas regras (conhecidas como "regras de produção").
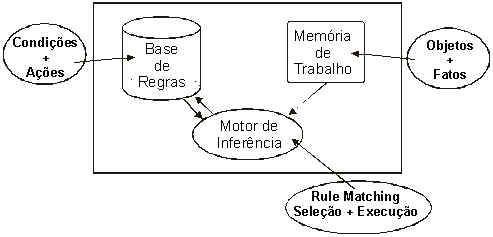
Uma parte do programa (o motor de inferências) é o responsável por encontrar regras que sejam adequadas à situação corrente que se deseja resolver. As regras tem um formato genérico, onde uma condição antecedente é seguida por uma ação consequente.
![]()
Se a condição apresentada pelo antecedente é satisfeita, então a ação especificada pelo consequente é executada. O exemplo abaixo apresenta um caso prático:

Toda vez que a temperatura do forno subir acima de 800 graus e o tempo de operação for superior a 15 segundos, o sistema irá fechar a válvula V3 e avisar o operador. Um sistema especialista pode dispor de centenas ou mesmo milhares de regras como essas, capturando boa parte do conhecimento de um "especialista" em determinado assunto. Mas esse conhecimento não ajuda muito o sistema na resolução de casos para os quais ele não estava "programado". Há uma grande dificuldade em lidar com os casos não previstos, as exceções, as situações incomuns. São dessa época algumas histórias de horror, na qual um sistema especialista de uma financeira aprovava um crédito para um jovem de 18 anos. Na ficha de solicitação do empréstimo, o rapaz dizia que trabalhava no mesmo emprego há 20 anos. Onde está a inteligência de um sistema desses?
CYC: Uma Aposta Muito Alta
A fragilidade dos sistemas especialistas sempre foi questionada e muitas tentativas de resolver o problema foram empreendidas. Talvez o mais ambicioso sistema simbólico jamais realizado com o expresso propósito de resolver a fragilidade dos sistemas especialistas seja o projeto Cyc (http://www.cyc.com).
Obra de Douglas Lenat, um brilhante pesquisador formado em Stanford, Cyc (de EnCYClopedia) é um sistema onde tudo é grande. O princípio básico desse sistema é obter inteligência a partir da explicitação de uma grande quantidade de conhecimento. Por mais de uma década, dedicados "engenheiros do conhecimento" colocaram no Cyc todo tipo de informação que faz parte do bom senso das pessoas. Veja alguns exemplos simples do tipo de informação inserida manualmente no Cyc:
Toda ave é um animal
Todo pardal é uma ave
Todo corvo é uma ave
Se ?x é uma ave e se ?x está sentindo dor,
Então ?x provoca empatia positiva
"Enquanto uma pessoa está dirigindo um carro,
contato visual com os olhos não é socialmente
requerido durante conversações"
"Todas as pessoas mortas permanecem mortas"
Em 1992, Cyc já contava com cerca de 1.400.000 asserções desse tipo em sua base de conhecimentos. É desse volume que Lenat e sua equipe esperam o nascer de um sistema inteligente, capaz, por exemplo, de ler o jornal do dia (Cyc, mesmo hoje, ainda não consegue esta proeza).
Além de uma base de conhecimentos gigantesca, o sistema Cyc dispõe de diversos métodos de inferência e de uma poderosa linguagem, a CycL. A sentença "todos os objetos possuidos por Sergio encontram-se na casa do Sergio" pode ser codificada em CycL desta forma:
(forAll ?x
(implies
(owns Sergio ?x)
(objectFound ?x CasaSergio)))
Essa construção tem bastante em comum com a linguagem LISP. A elegância e o poder da CycL garante boa parte do poder do sistema. E esse sistema consegue realmente surpreender. Cyc pode ser usado, por exemplo, como um "front-end" para aplicações de pesquisa em banco de dados. A pesquisa, em vez de ser uma query SQL, é uma frase em linguagem natural, digitada por uma pessoa sem treinamento específico. Cyc transforma a frase de sua expressão natural em uma expressão em CycL interna, que contenha uma correta tradução em termos de senso comum:
"Me mostre as pessoas que tenham formação
superior e que vivam em Ribeirão Preto"
Em um sistema SQL tradicional, se não houver um campo "formação superior" no banco de dados, essa requisição irá retornar sem mostrar nada. Mas o Cyc sabe interpretar o que significa "formação superior", e por isso sua tradução em CycL fica assim:
(and
(or
(isa ?x Professor)
(isa ?x Doutor)
(isa ?x Advogado)
(isa ?x Engenheiro))
(residesInRegion ?x RibeiraoPreto))
Nota-se o poder que isso agrega às consultas, pois agora temos um sistema que consegue entender além daquilo que perguntamos. É óbvio que isto é muito mais do que temos em nossos sistemas tradicionais. É indiscutível que isto avança muito em relação aos frágeis sistemas especialistas. Mas será que é isto que pode ser chamado de um computador inteligente? A questão fundamental que coloco aqui não é a quantidade nem a qualidade do conhecimento que Cyc dispõe, mas sim quem colocou esse conhecimento lá dentro. Se foi um ser humano, então não é o sistema que é inteligente, mas sim esse ser humano. Onde é que está a Inteligência Artificial em um sistema que precisa receber manualmente declarações tão triviais quanto "para entrar em uma sala precisamos abrir a porta antes"?
Alguns Problemas dos Sistemas Simbólicos
Como vimos, um dos grandes problemas da maioria dos sistemas simbólicos é a sua extrema dependência de seres humanos para alimentá-los e corrigi-los. Quando dizemos ao sistema que Piu-Piu é um pássaro estamos, na verdade, "resolvendo" grande parte do problema e codificando-o de uma forma totalmente arbitrária. Para um computador, dizer "Piu-Piu é um Pássaro" ou "Tkuyyiz é um Zthhizoe" significa exatamente a mesma coisa.
O que é mesmo um pássaro? Um pardal é um pássaro. Ora, um kiwi, aquela ave australiana, também é um pássaro. Mas enquanto o primeiro sabe voar, este último não sabe. Pássaros não nadam como peixe. Mas pinguins nadam, e são considerados pássaros. E pinguins não conseguem voar. Esse tipo de informação costuma desconcertar muitos sistemas simbólicos, pois eles não têm como categorizar ou mesmo adaptar suas categorias de acordo com suas próprias experiências. Dependem sempre de um operador humano que lhes informe sobre o assunto, de forma "mastigada". Meu ponto aqui é que se há um dedo humano para "corrigir" explicitamente todos os erros associados a um símbolo, então é porque o erro foi percebido por este ser humano, e desta forma ele é que é inteligente, e não o sistema.
Além disso, a habilidade de "voar" de todos os pássaros deveria ser automaticamente abstraída a partir de diversas instâncias específicas de pássaros que conseguem voar. Isto envolve habilidades indutivas, típicas do comportamento de crianças e essenciais à criação de conhecimento. Poucos sistemas simbólicos conseguem montar categorias indutivas com tal flexibilidade e aqueles que o fazem, não parecem usar os resultados desse aprendizado para modificar suas próprias expectativas em relação a futuras experiências, facilitando sua compreensão.
Outro ponto, associado às categorias indutivas, é o uso das experiências sensórias de um organismo inteligente para sustentar os conceitos simbólicos que eles utilizam. Aqueles sistemas que não dispõe desta sustentação estão à mercê de um sério problema de suporte, conhecido como "o problema do aterramento dos símbolos" (Harnad 1990).
Há mais deficiências dos sistemas simbólicos, em especial nos baseados em lógica. Uma delas é o crescimento exponencial do número de relações lógicas que é necessário investigar mesmo nos casos mais simples. Suponha que um sistema conheça alguns fatos sobre pássaros. Sabe, por exemplo, que pássaros voam. Então, ao afirmarmos que Tico é um pássaro, o sistema irá rapidamente concluir que ele pode voar, pois ele tem esta regra:![]()
E esta regra afirma que qualquer pássaro pode voar. Mas Tico não é um pássaro qualquer, ele tem um pequeno problema com suas asas, que são muito curtas. Logo, ele é um pássaro, tem asas, mas não pode voar, pois ele é "anormal". Para resolver isso, a expressão genérica acima teria que ser modificada para conter esta ressalva:
![]()
O símbolo '~' representa negação, ou seja, todo o pássaro pode voar contanto que ele não seja anormal. Mas será que ele não pode mesmo voar? E se colocarmos o Tico dentro de um avião? Agora, ele certamente poderá voar. Portanto, nossa expressão precisa levar em conta esse fator:
![]()
A expressão acima quer dizer isto: "Se x for um pássaro e x não for anormal ou então se x estiver em um avião, então x pode voar". Resolvemos todos os nossos problemas? Estamos longe disso.
Que acontece se o avião estiver sem combustível? E se faltar o piloto? E se o tempo não permitir a decolagem? E se a turbina estiver com problemas técnicos? E se o avião estiver dentro de um hangar trancado? Existe uma infinidade de motivos que poderiam impedir Tico de voar (e outra infinidade que o faria voar, como colocá-lo em uma catapulta e dispará-lo em direção ao céu).
Todos esses motivos precisariam estar explicitados nas condições lógicas, para que o sistema possa raciocinar corretamente. Sim, isso é possível, e boa parte dos sistemas baseados em lógica (como o próprio Cyc) esmeram-se em completar suas bases de conhecimento. Contudo, por causa da complexidade de nosso mundo, mesmo as situações mais mundanas exigiriam um gigantesco número de condições acessórias para que fosse minimamente útil. Cada uma dessas condições teria que ser investigada, mesmo nos casos de raciocínios banalmente simples. É claro que isto levaria qualquer sistema a uma rápida saturação, mesmo nas questões bem triviais (parte dessa questão tem relação com o "frame problem", um dos problemas que assombram os pesquisadores envolvidos com lógica; uma boa discussão dessa questão pode ser vista em Shanahan 1997).
Há várias formas de superar alguns desses dramas (uma delas é a Default Logic, proposta por Reiter, outra são as "microtheories" do Cyc), mas isto só introduz novas formas de remendar algo que parece estar errado desde o começo: um sistema que é inteligente não é aquele que consegue seguir as regras que estipulamos com precisão, mas sim aquele que descobre as regras por si próprio. Boa parte do que reconhecemos como comportamento inteligente está associado a essa habilidade autônoma de descobrir relações, associações, regras, padrões, sequências, conexões. Um sistema puramente simbólico não parece ter muito talento para isso.
Introduzindo o Conexionismo
Uma forte reação aos problemas dos métodos simbólicos veio através dos sistemas paralelos e distribuídos (PDP, Parallel Distributed Systems, Rumelhart & McClelland 1986, também popularmente conhecidos como redes neurais). Um dos pontos de partida dessa estratégia é observar o substrato básico de nosso cérebro, o neurônio.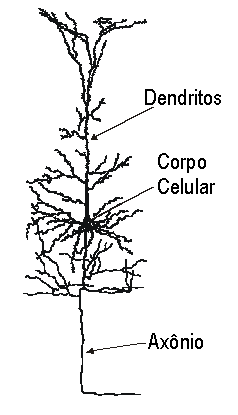
Um típico neurônio biológico dispõe de diversas entradas (os dendritos) e uma saída (o axônio; na verdade, as arquiteturas dos neurônios biológicos são muito mais complexas do que os diagramas tradicionalmente expostos; veja, por exemplo, Rieke et al. 1998). Assume-se que a operação executada nesse neurônio seja uma soma ponderada dos impulsos provenientes de cada dendrito. Disto vem um modelo básico (chamado de combinador linear adaptativo) que é a base para a construção de sofisticadas arquiteturas. Uma dessas arquiteturas é o perceptron multinível:
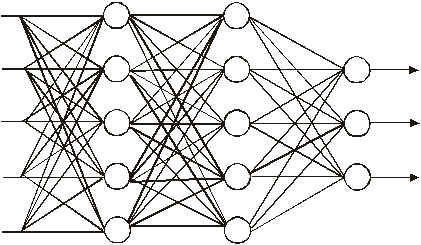
A entrada de sinais acontece à esquerda e a saída à direita. Esses modelos têm sido muito úteis em aplicações que envolvem reconhecimento de padrões, associação, classificação e muitas outras. Há diversas aplicações práticas que hoje operam baseadas nesses princípios. A operação básica dessas redes ocorre através de uma noção muito simples: a generalização. Sinais de entrada similares aos sinais que foram usados para treinamento fazem a rede ter comportamento na saída também similar (outros tipos de redes, chamadas de não supervisionadas, conseguem "descobrir" padrões mesmo sem serem treinadas especificamente para isso; Arbib 1995 é uma excelente referência sobre essas arquiteturas). Vem daí um grande potencial para aplicações, que vão de controle de instalações industriais, análise de crédito, previsão no mercado financeiro, classificação de sinais, etc.
Mas em nosso caso, queremos uma arquitetura que seja capaz de generalizar de forma inteligente, ou seja, obtendo os mesmos tipos de resultados que um ser humano teria se analisasse os mesmos dados. O uso de redes neurais na modelagem da cognição humana tem sido bastante bem sucedido, com exposições bastante convincentes (veja, por exemplo, Elman et al. 1996).
Um exemplo do tipo de generalização que esses modelos conseguem pode ser visto na rede a seguir (de Rumelhart e Todd, 1993).
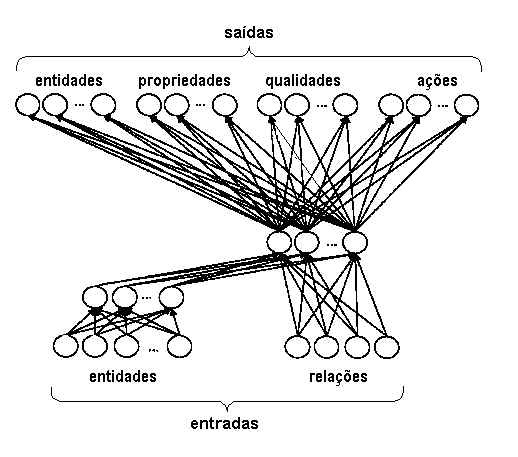
Essa rede é capaz de aprender relações muito interessantes, como estas:
Peixes têm barbatanas
Pássaros têm asas
Pássaros têm penas
Pássaros são animais
A partir de novos exemplares, a rede é capaz de inferir propriedades desses exemplares automaticamente. Assim, após treinarmos a rede com as características de um pássaro, se ensinarmos que "Rouxinol é um Pássaro" a rede irá inferir, por sua conta, todas estas propriedades:
Rouxinol tem penas
Rouxinol tem asas
Rouxinol pode voar
Sucessos como esses têm alimentado as esperanças dos cientistas que procuram modelar a cognição humana através de mecanismos distribuídos. Entretanto, ainda há problemas não resolvidos. Um deles foi detectado por Marcus (2001) exatamente nesse modelo que citamos. Após a introdução de proposições convencionais, Marcus treinou a rede com isto:
Pinguim é um pássaro
Pinguim não pode voar
Isto confundiu a rede, pois sua estratégia básica é tentar fixar-se, tanto quanto possível, em princípios generalizadores, e não em exceções individuais. Perguntado sobre Pinguins, a rede respondeu:
Pinguim é um peixe
Pinguim tem barbatanas
Pinguim tem penas
Essas respostas, obviamente, não estão certas, mas esse tipo de erro de generalização excessiva também costuma acontecer com crianças (casos típicos ocorrem com os erros na formação do tempo passado em verbos, conforme relata Pinker 1999). Nossa alternativa, assim como fazemos com as crianças, é insistir, treinando a rede nos conceitos que queremos enfatizar. Foi isso o que Marcus fez:
Pinguim é um pássaro
Pinguim pode nadar
Pinguim não pode voar
Entretanto, o resultado de nossa insistência, em vez de corrigir, complicou mais ainda as coisas, pois agora a rede responde que "Pássaros não podem voar".
A excessiva tendência à generalização, a incapacidade de aprender instâncias que sejam exceções de regras e a subsequente perda de generalizações anteriores decorre de um fenômeno chamado de interferência catastrófica, que é uma das pedras nos sapatos dos conexionistas (McCloskey & Cohen 1989, Marcus 2001). Além disso, ainda há muita dificuldade em fazer as redes neurais operarem sobre raciocínios lógicos, entendimento de linguagem natural e manipulação de símbolos de forma genérica, feito que é obtido até mesmo por bebês. Neste último caso, em particular, Marcus e colegas identificaram novos problemas que colocaram os conexionistas para coçar suas cabeças (veja Marcus et al. 1999, Marcus 2001).
Algoritmos Genéticos
Desde que Charles Darwin concebeu os princípios da teoria da evolução no século XIX, a ciência tem sido sistematicamente enriquecida pela aplicação do pensamento evolucionista. Além das implicações biológicas, ecológicas e econômicas, a teoria da evolução tem também sugerido processos computacionais de busca que dispõe de inúmeras vantagens.

Um dos principais teóricos da aplicação computacional dos princípios evolucionistas tem sido John Holland. É dele alguns dos princípios fundamentais dessa nova estratégia. Assim como na evolução biológica, existe uma competição de diversas soluções para a sobrevivência. O mecanismo da seleção natural se encarrega de privilegiar aquelas soluções que dêem melhor condição de adaptação ao organismo.
As soluções genéticas precisam operar sobre uma codificação de nosso problema. Uma forma de fazer isto é estabelecendo uma forma de representar cada instância através de uma sequência de bits, como mostra a figura ao lado.
A junção desses bits irá formar uma "solução" potencial, que tem semelhanças com um "cromossomo" de um organismo vivo. Outras soluções possíveis (codificadas por outras sequências de bits) quando reunidas irão formar um conjunto de soluções, ou uma população.
Chegou a hora de fazer essas soluções competirem entre si. Isto é feito através do estabelecimento de uma função de avaliação (fitness) que irá revelar quais são as melhores soluções. As piores serão descartadas, as melhores irão "casar" entre si:
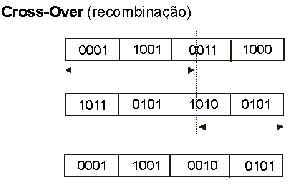
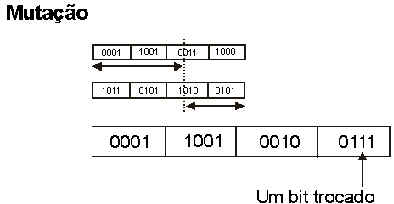
Com o crossover, partes das soluções que sobreviveram (as melhores) serão combinadas entre si, dando origem a novas soluções. Algumas dessas novas soluções ainda passam por um processo de mutação, no qual certos bits são aleatoriamente trocados.
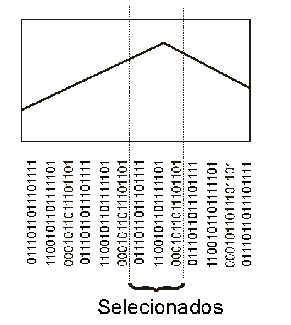
Esta redução é essencial, já que o número total de soluções iniciais desses problemas pode ser simplesmente astronômico.
O ciclo se repete até que tenhamos algumas (ou, às vezes, apenas uma) solução que satisfaça nossos requisitos. Esse poderoso processo, embora lento, pode descobrir soluções mesmo para problemas muito difíceis, para os quais não tenhamos uma solução formal (um problema desse tipo é a solução do melhor roteiro de caixeiros-viajantes, o conhecido problema TSP, Travelling Salesman Problem).
Data Mining: Ouro de Dados?
Com a utilização intensiva de computadores pelas empresas, uma imensa quantidade de dados foi sendo acumulado. São registros de processos produtivos, informações comerciais, dados estratégicos, relatórios, bancos de dados, ritmo de vendas, dados de clientes, etc. Será que há algum conhecimento importante a ser descoberto dessa montanha de dados?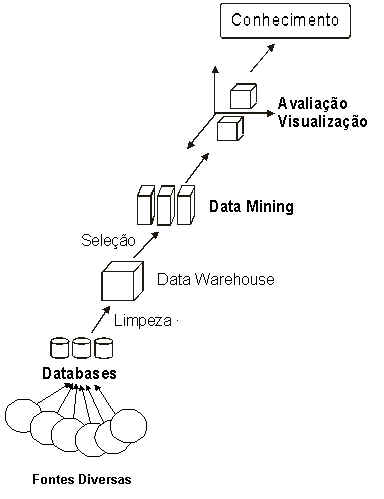
O Data Mining é composto por uma série de estratégias que visam responder afirmativamente a essa questão. Utilizando técnicas e algoritmos desenvolvidos pela IA, além de métodos estatísticos tradicionais, o Data Mining se propõe a encontrar padrões dentro desse gigantesco volume de dados. Esses padrões podem revelar surpresas e detalhes sobre o negócio que não eram conhecidos. Um valor incalculável pode estar escondido no meio desses dados.
Um dos exemplos de padrões que podem ser encontrados é a descoberta de associações entre itens de tal forma que a presença de um item implica na presença de um outro item específico. Assim, ao se levantar os compradores de pão e leite em um supermercado, pode-se perceber que são também compradores de manteiga. Mas outras relações menos óbvias também podem ser descobertas, conforme os níveis de investigação vão sendo progressivamente refinados. Muitos compradores de leite costumam comprar pão. O data mining permite que se avance essa descoberta a níveis mais profundos:
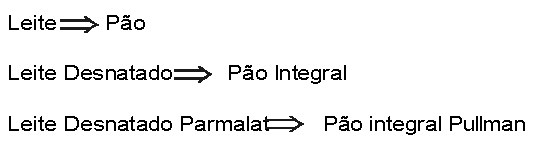
A descoberta desse novo conhecimento permite a um supermercado associar (colocar próximo) os produtos que são comprados em conjunto, maximizando as vendas de ambos. Esse mesmo tipo de tática também pode ser usado para diversas aplicações:
Uma técnica que muito contribui para o Data Mining é o ID3 (agora já superada por outras técnicas mais modernas, como o C4.5 e outras). Essa estratégia monta árvores de decisão a partir de tabelas como a apresentada abaixo:

Essa tabela lista o resultado de transações de empréstimo e algumas características de cada caso. No caso 7, por exemplo, o risco foi alto, o histórico de quem pediu o empréstimo é ruim, seu débito foi baixo, não apresentou nenhuma garantia (colateral) e seu salário anual é da ordem de R$ 15.000,00. A técnica transforma essa tabela em uma forma que generaliza alguns princípios (por isso é um método chamado de indutivo), permitindo que novos pedidos de empréstimo sejam avaliados com algum critério:
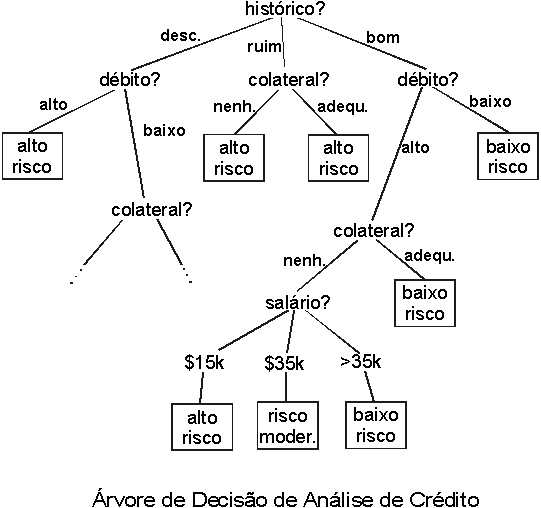
Dessa árvore, é fácil perceber que aqueles que dispõe de bom histórico e cujo débito seja baixo, representam baixo risco de operação. Já os que tem histórico desconhecido e tenham alto débito, representam alto risco.
A maioria das técnicas utilizadas em Data Mining tem essa característica de obter generalizações que permitem a descoberta de certos princípios essenciais do negócio, princípios esses que estavam "escondidos" debaixo de toneladas de dados brutos. É exatamente pelo fato de não serem óbvios que esses princípios são úteis e valiosos.
Agentes Inteligentes
O futuro parece que vai nos oferecer um tipo de programa inteligente que tem algumas características interessantes. Uma delas é a mobilidade: o programa poderá "circular" por outros ambientes para realizar suas tarefas. Outra é a sua habilidade de representar nossos interesses em algumas transações. O agente sabe o que queremos e está disposto a negociar com outros agentes (e mesmo com operadores humanos) para obter o melhor negócio.Por ter certa autonomia em negociar, as instruções que damos ao agente não precisam ser tomadas "ao pé da letra". Como exemplo, suponha que especificamos ao agente que ele deve localizar uma oportunidade de negócio com 15% de margem de lucro. Pode ser uma especificação complexa, com diversos fatores que podem ser negociados em conjunto (prazo, quantidade, etc). O agente poderá tolerar aceitar um negócio de alguém que ofereça somente 13% de lucro, mesmo sabendo que isso não atinge o que especificamos, principalmente se as demais condições do negócio forem satisfatórias. O agente poderá, por exemplo, saber que não deve fazer negócios com empresas em dificuldades financeiras pois o risco seria alto.
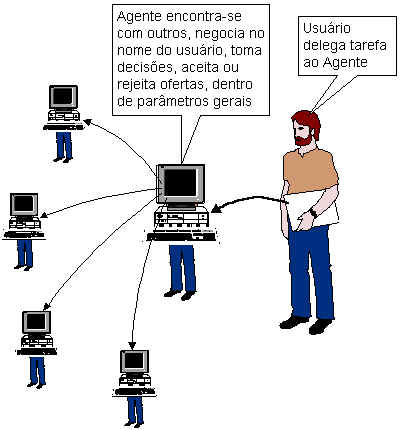
Esses agentes estão sendo pensados para dispor de um certo grau de relacionamento empático com o usuário, até mesmo com a simulação de algumas emoções. Essa relação empática permite que o agente se adapte mais facilmente ao momento emocional do usuário e com isso consiga ampliar sua utilidade (veja mais sobre isto em Ford et al. 1995 e Picard 1997).
Ainda é prematuro opinar até que ponto conseguiremos obter agentes com tamanho grau de autonomia e habilidade empática. Só o que podemos antever é a necessidade de programas que tenham a habilidade de aprender por experiência própria, com um mínimo número de regras inseridas manualmente.
Conclusão
Durante os quase cinquenta anos de pesquisa desde que a Inteligência Artificial recebeu seu nome, aprendemos e criamos muito. Neste artigo mal tocamos na riqueza e variedade de teorias e técnicas brilhantes desenvolvidas durante todo esse período. Parece fato que nosso aprendizado durante esse tempo todo deveu-se mais aos erros do que aos acertos. Isto só revela que o problema de obter inteligência em máquinas é realmente complexo.
Se os sistemas simbólicos demonstram certas fraquezas, também os conexionistas tem a sua quota de problemas. Há um grande número de pesquisadores que estão apostando atualmente em soluções híbridas, onde o simbólico convive com o neural (Wermter & Sun 2000). São tentativas que só o futuro poderá classificar como bem sucedidas ou não.
Mas se há algo que realmente parece estar despontando como promissor no futuro é a compreensão de que inteligência é uma habilidade que requer contato sensório íntimo e intenso com o mundo (desenvolvo melhor este tópico em Navega 2000). Organismos inteligentes têm uma especial atenção ao nível perceptual, aquele nível que consegue, por exemplo, discriminar uma maçã de um tomate. Inteligência requer, também, o equivalente de um "corpo físico" que permita ao agente explorar suas circunvizinhanças e assim obter uma oportunidade de interação (Clark 1997). Boa parte daquilo que um sistema pode conhecer provêm justamente da qualidade dessa interação.
Mais do que pesquisar algoritmos e técnicas, o que a IA precisa hoje é compreender os processos que ocorrem nas mentes das crianças. São elas nosso principal exemplo de entidades que conseguem obter conhecimentos a partir de sua interação com o mundo, até mesmo (ou principalmente) enquanto estão brincando despreocupadamente. Na sua transformação para adultos está toda a sequência que precisa ser replicada em máquinas inteligentes. Inteligência não parece ser uma característica automaticamente possuida por sistemas com muito conhecimento. Inteligência parece ser uma característica daqueles sistemas capazes de gerar conhecimento por seus próprios esforços, sejam eles através de acertos ou de fracassos.
Um sistema desse tipo vai acabar naturalmente com muito conhecimento, mas ao contrário daqueles programas que sempre foram alimentados manualmente, este pode crescer por conta própria. Afinal, o que nós desejamos não é mais uma enciclopédia eletrônica em CD-ROM. O que queremos é um companheiro ativo, criativo e inteligente, que nos ajude a resolver os problemas que teremos pela frente, justamente aqueles problemas para os quais ainda não temos solução.
Agradecimentos
O autor agradece a Intelliwise Research and Training por suporte durante a elaboração deste artigo. Parte do material exposto aqui foi desenvolvido pelo autor durante curso que ministrou para a OPP Petroquímica entre 2000 e 2001.Referências
Anderson, James A. (1995) An Introduction to Neural Networks. MIT Press, Massachusetts.
Arbib, Michael (ed) (1995) The Handbook of Brain Theory and Neural Networks. MIT Press, Massachusetts.
Barr, Avron; Cohen, Paul R.; Feigenbaum, Edward A. (1989) The Handbook of Artificial Intelligence, Vol. IV. Addison-Wesley Publishing, Inc. Massachusetts.
Barr, Avron; Feigenbaum, Edward A. (1982) The Handbook of Artificial Intelligence, Vol. II. Addison-Wesley Publishing, Inc.Massachusetts.
Bittencourt, Guilherme (1998) Inteligência Artificial, Ferramentas e Teorias. Editora da UFSC, Florianópolis.
Boden, Margaret A. (ed) (1996) Artificial Intelligence. Academic Press, Inc., San Diego.
Clark, Andy (1997) Being There, Putting Brain, Body, and World Together Again. Bradford Book, MIT Press, Massachusetts.
Dean, Thomas; Allen, James; Aloimonos, Yiannis (1995) Artificial Intelligence, Theory and Practice. The Benjamin/Cummins Publishing Company, Inc., California.
Dreyfus, Hubert L. (1992) What Computers Still Can't Do. The MIT Press, London, England
Elman, Jeffrey L.; Bates, Elisabeth A.; Johnson, Mark H.; Karmiloff-Smith, Annette; Parisi, Domenico, Plunkett, Kim (1996) Rethinking Innateness. Bradford book, MIT Press, Massachusetts.
Ford, Kenneth M.; Glymour, Clark; Hayes, Patrick J. (1995) Android Epistemology. AAAI Press, Menlo Park.
Franklin, Stan (1995) Artificial Minds. MIT Press, Massachusetts.
Fyfe, Colin (1996) Artificial Neural Networks and Information Theory. University of Paisley.
Ginsberg, Matt (1993) Essentials of Artificial Intelligence. Morgan Kaufmann Publishers, Inc., San Francisco, CA.
Han, Jiawei; Fu, Yongjian (1995) Discovery of Multiple-Level Association Rules From Large Databases. Proceedings of 21st VLDB Conference.
Han, Jiawei; Chen, Ming-Syan; Yu, Philip S. (1996) Data Mining: An Overview from Database Perspective
Hand, David J. (1999) Statistics and Data Mining: Intersecting Disciplines, In: SIGKDD Explorations, Vol 1, Issue 1
Harnad, Stevan (1990) The Symbol Grounding Problem. Physica D 42: 335-346.
Holland, John H. (1992) Adaptation in Natural and Artificial Systems. MIT Press,Massachusetts..
Holland, John H. (1995) Hidden Order, How Adaptation Builds Complexity. Helix Books, Massachusetts.
Holland, John H. (1998) Emergence, From Chaos to Order. Helix Books, Massachusetts.
Holsheimer, M.; Siebes, A. P. (1994) Data Mining: The Search for Knowledge in Databases. Centrum Voor Wiskunde en Informatica, CS-R9406.
Jackson Jr, Philip C. (1985) Introduction to Artificial Intelligence, Second Edition. Dover Publications Inc., New York.
Kettler, Brian; Andersen, William; Hendler, James; Luke, Sean (1995) Using the Parka Parallel Knowledge Representation System. University of Maryland technical report CS-TR-3485.
Kosko, Bart (1992) Neural Networks and Fuzzy Systems. Prentice Hall, Inc. New Jersey.
Lenat, Douglas B.; Guha, R. V. (1990) Building Large Knowledge-Based Systems. Addison-Wesley Publishing Company, Inc., New York.
Mahesh, Kavi; Nirenburg, S.; Cowie, J.; Farwell, D. (1996) An Assessment of CYC for Natural Language Processing. Computing Research Laboratory, New Mexico State University http://crl.nmsu.edu/Research/Pubs/MCCS/Postscript/mccs-96-302.ps
Marcus, Gary F.; Vijayan, S.; Bandi Rao, S.; Vishton, P. M.. (1999) Rule Learning in Seven-Month- Old Infants. Science, 283, 77-80.
Marcus, Gary F. (2001) The Algebraic Mind. Bradford Book, MIT Press, Massachusetts.
McCloskey, M.; Cohen, N. J. (1989) Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. In: G. H. Bower (ed) The Psychology of Learning and Motivation: Advances in Research and Theory, 24 (pp. 109-165). Academic Press, San Diego.
Minsky, Marvin (1975) A Framework for Representing Knowledge. In: Winston, Patrick H. (ed) The Psychology of Computer Vision. McGraw-Hill, New York.
Mitchell, Tom (1997) Machine Learning. The McGraw-Hill Company, Inc., New York
Munakata, Toshinori (1998) Fundamentals of the New Artificial Intelligence. Springer-Verlag New York, Inc.
Navega, Sergio C. (2000) Inteligência Artificial, Educação de Crianças e o Cérebro Humano. Leopoldianum, Revista de Estudos de Comunicações da Universidade de Santos, Ano 25, No.72, Fev. 2000, pp 87-102. (http://www.intelliwise.com/reports/p4port.htm)
Newell, Allen; Simon, Herbert (1976) Computer Science as Empirical Enquiry: Symbols and Search. In Haugeland, John (ed.) (1997) Mind Design II, MIT Press, Massachusetts.
Nilsson, Nils J. (1998) Artificial Intelligence, A New Synthesis. Morgan Kauffmann Publishers, Inc., San Francisco, CA.
Picard, Rosalind W. (1997) Affective Computing. MIT Press, Massachusetts.
Pinker, Steven (1999) Words and Rules. Basic Books, New York.
Reiter, R. (1980) A Logic for Default Reasoning. Artificial Intelligence, 13 (1-2): 81-132.
Rich, Elaine; Knight, Kevin (1994) Inteligência Artificial. Makron Books do Brasil Editora Ltda, São Paulo.
Rumelhart, David E.; McClelland, James (1986) Parallel Distributed Processing. Bradford Book, MIT Press, Massachusetts.
Rumelhart, David E.; Todd, P. M. (1993) Learning and Connectionist Representations. In D. E. Meyer & S. Kornblum (eds.), Attention and Performance, XIV. MIT Press, Massachusetts.
Riddle, Patricia (et. al) (1992) CYC Evaluation. Boeing Computer Services Technical Report.
Rieke, Fred; Warland, David; van Steveninck, Rob de Ruyter; Bialek, William (1998) Spikes, Exploring the Neural Code. Bradford Book, MIT, Massachusetts.
Russell, Stuart, Norvig, Peter (1995) Artificial Intelligence, A Modern Approach, Prentice-Hall, Inc.
Shanahan, Murray (1997) Solving the Frame Problem. MIT Press, Massachusetts.
Sowa, John F. (ed.) (1991) Principles of Semantic Networks. Morgan Kaufmann Publishers, Inc., San Mateo, CA.
Stefik, Mark (1995) Introduction to Knowledge Systems. Morgan Kaufmann Publishers, Inc., San Francisco, CA.
Tveter, Donald R. (1998) The Pattern Recognition Basis of Artificial Intelligence. IEEE Computer Society, New Jersey.
Wermter, Stefan; Sun, Ron (eds) (2000) Hybrid Neural Systems. Springer-Verlag Berlin, Germany.
Yuret, Deniz (1996) The Binding Roots of Symbolic AI: A brief review of the CYC project. MIT Artificial Intelligence Laboratory Technical Report.
Zurada, Jacek M. (1992) Introduction to Artificial Neural Systems. PWS Publishing Company, Minesota
Retorna à página de publicações